
1.- ¿Qué es el RGPD?
La protección de los datos personales siempre ha sido un objetivo político a conseguir en la Unión Europea. Por ello se consagró en el artículo 8 de la Carta de los Derechos Fundamentales de la Unión Europea. En la actualidad los datos personales se han convertido en un activo cada vez más valioso para muchas empresas, ofreciendo sus servicios a coste cero para luego recopilar información personal que pueda monetizarse, mayormente mediante anuncios. Dichos modelo de negocio nos permite acceder de forma gratuita a multitud de servicios de gran calidad, pero generan también numerosas situaciones donde las empresas hacen un uso indebido de los datos personales. Algo que por desgracia comienza a ser muy común y condiciona nuestro derecho a la protección de datos personales. Con la intención de salvaguardar ese derecho fundamental y mejorar muchos de los puntos débiles de la ya derogada Directiva 95/46/CE, por ejemplo la falta de homogeneidad en la libre circulación de datos en Europa, llegó el RGPD. De esta forma el Reglamento General de Protección de datos o RGPD, aplicable desde el 25 de mayo de 2018, establece las nuevas normas relativas a la protección de las personas físicas en lo que respecta al tratamiento de sus datos personales y la libre circulación de estos datos. El RGPD supone numerosos avances en la gestión de datos personales en la Unión Europea e incluso más allá, ya que su ámbito de aplicación material y territorial es muy amplio. Además, está pensado para esta nueva economía del dato que se ha creado en la última década, creando nuevas obligaciones a los proveedores y generando nuevos derechos para sus usuarios. Además, convierte en norma los conceptos de privacidad desde el diseño y por defecto. Algo que como veremos resulta muy importante para nuestra paradoja. Por todo ello, el RGPD se convierte en esta fuerza imparable que toda organización que gestione información personal, el petróleo de nuestros días, debe tener en consideración. Ahora bien, el RGPD se redactó bajo un modelo tradicional y centralizado en cuanto a la gestión de los datos. Es decir, un mundo en el que los datos personales serían tratados por unos responsables y encargados (relativamente) fáciles de identificar y con una estructura suficientemente jerarquizada. Con lo que no contaba el legislador, si bien tuvo la oportunidad de saber sobre ello ya que blockchain nace en 2009 junto a bitcoin, es que en nuestros días la gestión de datos personales también se iba a producir en entornos absolutamente descentralizados y mayormente automatizados. O lo que es lo mismo, entornos en los que identificar a responsables, encargados o interesados iba a ser una tarea altamente compleja. He aquí la cadena de bloques y el desafío que plantea al RGPD y buena parte de sus principios.
2.- ¿Qué es Blockchain?
Una vez presentada nuestra fuerza imparable, el RGPD, vamos con el otro protagonista de esta historia: el objeto inamovible o blockchain. Una buena introducción al tema puede ser el siguiente vídeo de la Universidad de Deusto:
Sea como sea, ¿cómo puede definirse blockchain? Si nos ponemos técnicos, una blockchain o cadena de bloques sería una base de datos en la que la información contenida se agrupa en bloques a los que se les añaden metainformaciones relativas a otro bloque de la cadena anterior en una línea temporal. De esa manera, y gracias a técnicas criptográficas, la información contenida en un bloque solo puede ser rechazada o editada modificando todos los bloques posteriores.
Si lo bajamos al suelo, blockchain no es más que una base de datos especial. En esa base de datos hay una hoja de cálculo que se ha duplicado miles o millones de veces en una red de ordenadores. Esa red de ordenadores actualiza de forma regular y simultánea esa hoja de cálculo cada vez que hay un cambio en la misma. Añadido un cambio, el mismo no puede ser editado o borrado, solo rectificado con otro cambio posterior.
Como esa misma base de datos existe en centenares de miles o millones de ordenadores a la vez (también llamados nodos), no hay una localización central para su gestión, lo que dificulta muy considerablemente su hackeo, facilita su verificación y distribuye la confianza sobre la veracidad de esos datos en todos los ordenadores de la red y no en una ubicación central. Ahora bien, también rompe con el modelo tradicional de bases de datos centralizadas.
Quien tenga más curiosidad sobre ello, puede ampliar información en este post nuestro sobre el tema.
Dicho esto, en una blockchain un bloque será la estructura de datos utilizada para agrupar transacciones (por ej. un pago con criptomonedas). Cada vez que un bloque es completado el mismo es añadido a la cadena.
Además de las transacciones, los bloques incluyen otros elementos, como el hash del bloque anterior (una especie de huella dactilar en versión digital del mismo) y una marca de tiempo (día, hora, fecha).
Volveremos a varios de estos conceptos y términos a lo largo del texto. Por ahora basta que nos quedemos con la idea de que blockchain es una base de datos descentralizada (que por tanto puede contener datos personales) y entre cuyas características se incluye la inmutabilidad de lo escrito en la misma.
Como seguro que muchos ya saben, blockchain se está usando en múltiples sectores económicos. En los sectores inmobiliario, del comercio, financiero, del transporte, seguros o logística, entre otros. La idea es que una sola base de datos con una única versión de los datos anotados puede simplificar mucho la vida a las empresas y entidades, en especial a la hora de coordinar y validar sus actividades en cualquier parte del mundo. Evitando con ello la interoperabilidad entre múltiples bases de datos e intermediarios.
Muy resumidamente, he ahí nuestro objeto inamovible.
2.1.- Tipo de nodos y de cadenas
Antes de seguir con este enfrentamiento épico, sería bueno perfilar toda una serie de cuestiones sobre el funcionamiento de blockchain. La cadena de bloques tiene como característica básica ser una tecnología para bases de datos descentralizadas. Eso permite que un gran número de participantes (conocidos o no, enemistados o no), pueda almacenar de forma sincronizada copias de la misma información. Datos que únicamente pueden ser añadidos pero no eliminados. Ahora bien, eso puede matizarse mucho en función de la tecnología y el tipo de blockchain utilizado. Ello nos lleva a hablar de tipos de blockchain y nodos. En este caso, de acuerdo a la clasificación establecida por el European Union Blockchain Observatory and Forum. Comencemos con los nodos. En términos generales, una blockchain consiste en un servidor compuesto por un grupo de nodos (ordenadores) que almacenan copias sincronizadas de la misma información. Normalmente hay dos tipos de nodos: A) Nodos de validación: son específicos de una red y además de realizar operaciones de validación deben resolver un conjunto de problemas criptográficos antes de poder incorporar un nuevo bloque a la cadena. Por tanto, para crear un nuevo bloque válido deben seguir las reglas exactas especificadas por el algoritmo de consenso de la cadena. Para ello ponen a disposición de la red su poder computacional (capacidad de CPU y sobre todo GPU), con los gastos energéticos y a nivel de infraestructura que ello comporta. Por realizar esa tarea reciben una compensación. A esa acción se le llama minería, siendo los nodos validadores los mineros. De ese modo, el primer nodo validador que consigue resolver el problema criptográfico planteado recibe una pequeña comisión por ello. B) Nodos de participación: son los que almacenan copias sincronizadas de la información. En función de la tecnología específica de la cadena, los nodos almacenarán toda la información de la cadena o solo una parte (para así evitar que ser parte de la cadena le deje a uno sin espacio libre en el disco duro). Si un usuario se conecta a un nodo de participación puede añadir datos a la cadena, pero esa transacción deberá ser validada por un nodo de validación. Dicho esto, vamos a por los diferentes tipos de cadenas de bloques. Inicialmente solo se hablaba de BLOCKCHAIN PÚBLICAS, con permisos y sin permisos. Las blockchain públicas sin permisos serían como Bitcoin o Ethereum. Las mismas se caracterizan por no exigir a los usuarios el cumplimiento de ningún requisito para unirse a ella. Es decir, cualquiera puede convertirse en un nodo o parte de la red. Por eso normalmente se dice que son cadenas sin permisos. Para hacerlo simplemente hay que instalar el software cliente (software que casi siempre es de código abierto) y descargar una copia completa de la cadena de bloques. A partir de ese momento ya eres un nodo completo que puede participar en el proceso de almacenamiento y/o agregación de información (participación o validación). Asimismo, el contenido de una blockchain pública es transparente y visible para todos los usuarios (y en algunos casos no usuarios), ya que habitualmente no se exigen permisos o invitaciones para poder acceder y participar. Por otro lado tenemos las blockchain públicas con permisos. O lo que es lo mismo, en éstas cualquiera puede ser un nodo de participación y ver todos los datos, pero solo los usuarios aprobados previamente pueden ser nodos de validación y añadir datos a la cadena. Sería por ejemplo el caso de Alastria, entre otros.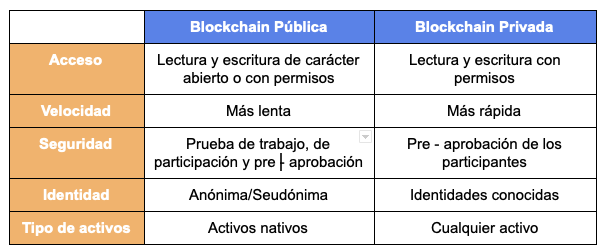

3.- La tensión entre blockchain y el RGPD
3.1.- Los escenarios
Conocidos nuestros protagonistas y sus características, es hora de comenzar a profundizar en la problemática. Para empezar, es importante recordar que el cumplimiento del RGPD no tiene que ver con la tecnología blockchain en sí, sino en cómo se utiliza la misma. Es decir, al igual que no hay un Internet o un algoritmo compatible con el RGPD, no existe una tecnología de cadena de bloques compatible con el reglamento. Como bien dice el informe del European Union Blockchain Observatory and Forum, solo hay casos de uso y aplicaciones que podrían llegar a ser compatibles. De esta manera, debemos entender que la interacción entre blockchain y el RGPD debe realizarse caso por caso, analizando dónde aparecen los datos personales, cómo se tratan y quiénes son los responsables de dicho tratamiento. De los tres escenarios más comunes comentados (blockchain públicas sin permisos, blockchain públicas con permisos y blockchain privadas), ya avanzamos que son éstas últimas las que de inicio mejor van a llevarse con el RGPD. Los escenarios serían: A) Las cadenas privadas suelen estar operadas por empresas, consorcios o entidades gubernamentales, lo que facilita aplicar el contenido del RGPD. Dichas entidades están en posición de definir los roles de sus participantes y los flujos de información. Además, pueden imponer reglas estrictas de tratamiento de los datos personales al asegurarse de que todos los participantes de la red se vinculen con un conjunto de términos y condiciones. Sin embargo, también presentan desafíos. Es decir, solo porque los miembros de la entidad estén vinculados a unos términos y condiciones no significa que todos tengan una razón legítima para ver los datos de cada uno de ellos. B) En cuanto a las cadenas públicas con permisos, son una de las formas más comunes de operar, y se sitúan en un punto intermedio a la hora de hacerlas compatibles con el RGPD. C) Finalmente, las cadenas públicas sin permisos presentan sin duda los mayores desafíos respecto al cumplimiento de RGPD, debido a su naturaleza extremadamente distribuida.3.2.- Los puntos de tensión
Dicho esto, veamos dónde chocan nuestra fuerza imparable (el RGPD) y el objeto inamovible (blockchain), teniendo en cuentas los diferentes escenarios y particularidades de cada uno. Como decíamos al inicio, hay 4 materias aparentemente irreconciliables: 1) la identificación clara y centralizada de responsables, encargados e interesados frente a un sistema altamente descentralizado; 2) minimizar los riesgos para los interesados al subir datos a la cadena, de modo que deba recurrirse al cifrado de la información personal subida (si es que llega a subirse); 3) el ejercicio de derechos, y en especial el derecho de supresión teniendo en cuenta la inmutabilidad de la cadena; y 4) la prohibición (con límites) de decisiones individuales automatizadas en el caso de “contratos inteligentes” autoejecutables e irrevocables, ejecutados en la cadena. ¡Comencemos con el primero!
3.2.1.- Quién es el responsable
En el RGPD la accountability o el principio de responsabilidad pro activa viene regulado en los artículo 5.2 y 24, además del considerando 74. No es un concepto precisamente nuevo, ya la OECD hablaba del mismo en los Códigos de conducta o Guías de protección de la privacidad y flujo transfronterizo de datos personales, por allá 1980. El GT 29, el actual EDPB, lo definió como un principio por el que los responsables del tratamiento ponen en marcha procedimientos y medidas eficaces para garantizar el cumplimiento de los principios y obligaciones establecidos en la normativa sobre privacidad, y poder así demostrar ante las autoridades el cumplimiento de la misma. O lo que es lo mismo, no simplemente cumplas, sino que demuestra que cumples. En el RGPD el principio de privacidad pro activa tiene gran importancia. En un modelo tradicional cliente – proveedor, es relativamente fácil identificar a las diferentes partes (responsable, encargado, interesado y demás) y hacerlo cumplir (importante resaltar lo de “relativamente”). Pero cuando el RGPD y su principio de privacidad pro activa entran en contacto con blockchain, los roces pueden ser significativos a la hora de identificar a las partes. Así las cosas, en las cadenas privadas y en las públicas con permisos es donde mejor encaja el modelo tradicional. De hecho, el informe de la agencia de protección de datos francesa (CNIL) sobre blockchain y el RGPD, recomienda que en los consorcios de blockchain se identifique al responsable o corresponsables tan pronto como sea posible en el proyecto. Es decir, la CNIL habla respecto a la existencia de corresponsabilidad, entendiéndola en este caso como un grupo de entidades o de personas que decidan realizar un tratamiento de datos personales utilizando blockchain. Sin embargo ,entiende que eso no será aplicable si se crea una persona jurídica en representación de todos los participantes, y la misma asume ser el responsable del tratamiento a todos los efectos. Igualmente cuando se designe a uno de los participantes como responsable del tratamiento. Por otro lado, en las blockchain públicas sin permisos, donde la idea es reemplazar el modelo tradicional de cliente – proveedor por uno basado en el tratamiento colectivo de datos a través de un protocolo compartido, la cuestión de cómo identificar a un responsable es mucho más compleja. Comencemos por, ¿quién no debería ser considerado responsable en esos casos? Sin duda, los desarrolladores de protocolos que crean y mantienen la tecnología de cadena de bloques de código abierto, como es el caso por ejemplo de bitcoin. ¿Razón? Son voluntarios que trabajan en un proyecto de código abierto y, en muchos casos, no reciben una compensación directa por sus esfuerzos. En esencia, simplemente crean una herramienta útil y ni siquiera informan de cómo se debe utilizar. Lo contrario sería como decir que Tim Berners-Lee es el responsable de todo lo que sucede en la World Wide Web. También sería deseable que los actores que ejecutan el protocolo de la cadena de bloques en sus ordenadores para actuar como nodos de validación o de participación en redes públicas sin permisos, no fueran considerados responsables del tratamiento. Pero aquí la cuestión no es tan pacífica. Por un lado, se puede argumentar que los nodos no determinan la finalidad ni los medios del tratamiento, ya que realmente: 1) están ejecutando el protocolo con la esperanza de ganar una recompensa; 2) para contribuir a la estabilidad de la red 3) o como una forma de acceder a los datos que son relevantes para ellos sin depender de intermediarios externos. De hecho, la CNIL señala en su informe que los mineros no sería responsables ya que simplemente validan transacciones y no delimitan las finalidades ni los medios para su tratamiento. Otros argumentan lo contrario, ya que a través de la acción de descargar y ejecutar activamente el software, los nodos determinan la finalidad y los medios del tratamiento. Además, apuntan que cuando se lanza una nueva versión de un protocolo, los nodos son libres de ejecutarlo o no, y a través de este acto influyen en cómo evoluciona la plataforma. Llegados a este punto, ¿qué pasa con los usuarios de la red que firman y envían transacciones a la cadena vía un nodo? Si envían datos personales como parte de una actividad comercial, lo más probable sería considerarlos como responsables del tratamiento. Esto incluiría entidades que operan software así como productos o servicios que publican datos personales en una cadena de bloques. Sin embargo, si envían sus propios datos personales para su uso personal, como la compraventa de criptos, seguramente estaríamos ante la excepción del artículo 2.2 c) RGPD de tratamiento de datos para uso doméstico. En este sentido, la CNIL entiende que podrán ser responsables del tratamiento todos aquellos que introduzcan datos personales en la blockchain siempre y cuando quien los introduzca sea una persona física y el tratamiento de datos personales esté relacionado con una actividad profesional o comercial. O bien, que quién los introduzca sea una persona jurídica. ¿Y el encargado del tratamiento, quién es? La CNIL entiende que podremos delimitar al encargado del tratamiento solo en supuestos concretos, por ejemplo:- Los desarrolladores de smart contracts que tengan acceso a datos personales de los usuarios de sus smart contracts.
- Los desarrolladores o validadores de transacciones, como son los mineros en las blockchain privadas o en las públicas con permisos, y bajo un protocolo de consenso de prueba de trabajo, cuando validan transacciones que contengan datos personales.

3.2.2.- La anonimización de los datos
El segundo punto de tensión es relativo a cómo los datos personales deberían ser anonimizados cuando se suben a una cadena de bloques. Es decir, cómo se minimizan los riesgos de los interesados cuando el tratamiento se realiza en blockchain. El RGPD se aplica al tratamiento de datos personales a menos que éstos se hayan anonimizado. Por tanto, no se aplica a datos anónimos. Sin embargo, el listón para lo que se califica como anónimo es muy alto. La técnica de anonimización no solo debe ser lo suficientemente buena para que sea imposible identificar a una persona física, sino que también el proceso debe ser irreversible. Es decir, no debería ser posible reconstituir los datos originales del dato anonimizado. Cualquier técnica que no cumpla con este estándar se consideraría “semi anónima”, y no anónima. Pero claro, los datos seudonimizados sí que están sujetos a las obligaciones del RGPD. Dada la inmutabilidad de los datos en la mayoría de las redes de blockchain, la comunidad entiende que almacenar datos personales en una cadena de bloques, sin ningún tipo de cifrado, es una mala idea. Recomendación aplicable tanto a las redes públicas como a las privadas, y sus diferentes variantes. A ello se suma el principio de privacidad desde el diseño, como señala el art. 25 RGPD. La CNIL dice que de acuerdo al mismo el responsable del tratamiento debe pensarse muy mucho si el tratamiento de los datos mediante blockchain es la tecnología más apropiada. Al fin y al cabo, en la cadena de bloques se dan dos circunstancias que sí o sí pueden implicar el tratamiento de datos: 1) una solicitud a millones de mineros para validar la transacción 2) la actualización de la cadena al añadir un nuevo bloque para todos los participantes. Eso genera un problema extra, dice la CNIL: que se produzcan transferencias internacionales de datos a terceros países y fuera de la UE. Algo que puede ocurrir muy fácilmente. Ese problema es más controlable en blockchains privadas o públicas con permisos, al poder aplicar cláusulas contractuales estándar, normas corporativas vinculantes, códigos de conducta o certificaciones. Pero cuando pasamos a una blockchain pública sin permisos, no hay límite a esas transferencias internacionales. Lo que genera nuestra segundo punto de tensión: cómo subimos datos personales a una blockchain minimizando los riesgos para los interesados, especialmente teniendo en cuenta características de la tecnología como su inmutabilidad o descentralización. Normalmente se habla de solucionar estos problemas mediante técnicas de ofuscación, cifrado o agregación para el tratamiento de datos personales. Y ya sea en un caso o en otro, el informe del European Union Blockchain Observatory and Forum dice que deben evaluarse dos riesgos cuando se adoptan algunas de estas técnicas: A) Riesgo de reversión: cuando a pesar de la técnica criptográfica utilizada, es posible revertir el proceso y reconstituir los datos originales. Por ejemplo, mediante el descifrado de fuerza bruta. B) Riesgo de vinculación: cuando cabe la posibilidad de vincular datos cifrados a una persona mediante el examen de los patrones de uso o contexto, o por comparación con otras piezas de información. Vamos a detenernos en cada una de las técnicas y comentar varias de sus particularidades. Recordemos que lo deseado es poder convertir los datos personales subidos a la cadena en totalmente anónimos, eliminando así de la ecuación a la fuerza irresistible conocida como RGPD. O si no fuera posible, minimizar su impacto. I.- Ofuscación de direcciones personales Vaya por delante que según el Diccionario de la Real Academia, “ofuscar” significa “oscurecer y hacer sombra” (entre otras acepciones). ¿Por qué puede resultar útil aquí? Ocurre que normalmente una cadena de bloques usa el sistema de “clave pública/privada” como un medio para proporcionar o derivar direcciones de los remitentes y receptores de las transacciones. Esa clave pública sería como el número de un apartado de correos. Yo puedo enviar información a ese buzón, pero solo el dueño de la clave privada puede abrirlo y obtener la información. Esa clave pública consiste en una larga cadena de caracteres aleatorios, de modo que en principio no hay forma de descubrir nada a partir de la misma. Dado que en algunas blockchains públicas las direcciones de los remitentes y receptores de las transacciones pueden ser vistas por todos, según el RGPD dichas direcciones serían datos seudonimizados, especialmente en los casos en que existe un claro riesgo de vinculación. Por ejemplo, cuando tengo mi clave pública visible en la bio de mi Twitter personal. De hecho, dice la CNIL que como las claves públicas son un elemento clave del funcionamiento de blockchain, son un dato que no puede minimizarse más y que su periodo de conservación está en línea con la existencia de la propia cadena. Es decir, si alguien usa la misma dirección para varias transacciones, entonces comienzan a surgir patrones. Estos patrones, quizás combinados con otros tipos de información, pueden usarse para identificar indirectamente a los individuos. Y estas técnicas ya se utilizan. En este contexto surge la ofuscación, que es por ejemplo el proceso que intenta modificar un programa para hacer más compleja su comprensión. La ofuscación perfecta es imposible, porque tarde o temprano hay que decirle al ordenador lo que tiene que hacer, pero pueden darse suficientes “rodeos” para confundir a quién esté analizando nuestro programa (ya sea un humano o una herramienta automática). Las técnicas de ofuscación normalmente se utilizan para: eliminar comentarios, espacios en blanco y saltos de línea; modificar los nombres de variables y funciones para que no proporcionen información sobre su objetivo; complicar artificialmente el control de flujo de un programa; alterar la distribución del código dentro de un proyecto o hacer que el código del programa se modifique a sí mismo antes de ejecutarse. Lógicamente estas técnicas pueden ayudar a anonimizar los datos personales de cara a su posible escritura en una blockchain. Por tanto, ¿cuáles son las técnicas de ofuscación más comunes? Una de ellas es la denominada servicio de direccionamiento indirecto de terceros. La misma consiste en pedir a un tercero que agregue muchas transacciones de blockchain y las publique en la cadena utilizando su clave pública propia. Es decir, lo que a veces sucede cuando alguien le pide a una plataforma de comercio electrónico que compre criptos en su nombre. La transacción individual de la persona generalmente no se revela en la cadena de bloques pública. Por tanto, esta primera técnica implica encubrir el significado de una comunicación haciéndola mucho más difícil de interpretar. Otra técnica son las llamadas firmas de anillo, mediante la cual múltiples partes firman una transacción determinada de manera que alguien externo puede estar seguro de que una de las partes es el firmante legítimo, pero no sabe cuál. Un ejemplo de firma de anillo podría ser usada para proporcionar una firma anónima de un funcionario de alto rango de un gobierno, sin revelar qué funcionario firmó el mensaje. Las firmas de anillo son adecuadas ya que su anonimato no puede ser revocado y porque el grupo para una firma de anillo puede ser improvisado (no requiere ninguna configuración previa). Sea como sea, las técnicas de ofuscación de direcciones se pueden implementar de muchas maneras, y será a la luz del RGPD que deberá examinarse caso por caso. II.- Cifrado de datos personales La criptografía es una materia muy técnica, pero simplificando, vamos a hablar de dos técnicas que son relevantes para el RGPD (dejamos otras más avanzadas para algo más adelante en el post): A) Cifrado reversible: El cifrado reversible implica mezclar una pieza de datos de tal manera que sus contenidos no puedan ser entendidos. Solo la persona en posesión de la clave de cifrado puede descifrarla. Existen varios tipos de cifrado reversible, como el cifrado simétrico (donde se usa la misma clave) para encriptación y descifrado y el asimétrica (donde se utilizan diferentes claves). Para quien quiera profundizar sobre la materia, ahí va un vídeo interesante: B) Hashing (cifrado no reversible): Las cadenas de bloques hacen un gran uso de hashes. ¿Pero qué son? Un hash criptográfico es una técnica matemática que permite generar una cadena de caracteres alfanuméricos de longitud fija y única a partir de cualquier conjunto de datos digitales. No hay límite en cuanto al tamaño del archivo que puede dar lugar al hash. Por tanto, cuando se ejecute la función siempre se obtendrá una frase de texto única de cierta longitud fija. Y lo que es más importante, si cambia incluso el dato más pequeño, el hash será radicalmente diferente. Lo que dejará claro que los datos subyacentes se modificaron. Por ello se dice que los hash son como huellas digitales, ya que no hay dos iguales. Ahí va otro vídeo interesante sobre la materia: ¿Para qué usa blockchain un hash? Entre otras cosas, para asegurar el estado actual de la cadena. De ese modo, la huella hace de sello para cerrar la cadena cada vez que un nuevo bloque es incorporado. Además, también sirve para referenciar de forma única datos que se mantinen fuera de la cadena. Hecha esta introducción al mundo de la criptografía, se nos plantea la siguiente pregunta ¿los datos personales cifrados mediante una técnica reversible, siguen siendo datos personales a la luz del RGPD? Pues aunque parezca mentira, sí. Ya que por muy sólido que sea el cifrado empleado en los datos, mientras la llave para revertirlo siga existiendo, pues no podemos hablar de dato anónimo. Si a eso le sumamos que la tecnología no deja de mejorar, y que cifrados seguros hace años ya no lo son, no hay técnica de cifrado reversible que sea completamente segura. ¿Y el hashing? Hemos dicho que es una técnica no reversible, ¿nos soluciona eso el problema? Pues estamos todavía en tierra de nadie en esta cuestión. Ahora mismo la mejor respuesta a la cuestión de si un dato personal hasheado es o no un dato personal (y por tanto aplicable el RGPD) sería: depende. ¿Y de qué depende? De si el tiempo y la tecnología identifican posibles riesgos de reversabilidad o vinculación. En cuanto al riesgo de reversibilidad, el Grupo de Trabajo del Artículo 29 ya dijo que un ataque de fuerza bruta podría revertir un hash si los datos originales son conocidos y no muy grandes. Este riesgo se intenta mitigar mediante el uso de técnicas llamadas “salting” (salteado) o “peppering” (pimentado), que implican agregar información adicional a los datos para hacerlos lo suficientemente grandes como para que un ataque de fuerza bruta no pueda tener éxito. La diferencia entre saltear o pimentar es que al saltear el creador del hash almacena fuera de la cadena la información salteada y el hash. Mientras tanto, pimentar implica que la información pimentada se almacena de forma secreta, o que ni tan siquiera se almacena. El otro riesgo del que hablábamos es el de vinculación. Es decir, hay situaciones en las que el análisis de patrones hace posible descubrir información sobre un individuo en particular. Por ejemplo, cuando un usuario determinado realiza una transacción, lo que permite analizar el tiempo y la frecuencia de la misma. En esos casos, podría descubrir todo el comportamiento de la transacción al enterarme de la fecha y hora específicas en que ésta se ha completado. En resumen, si el hashing de un dato personal implica el riesgo de reversión o de vinculación es algo que deberá analizarse caso por caso. Y todo ello sin saber qué postura acabarán adoptando las autoridades de protección de datos, el EDPB o los tribunales. Sin duda que para conocer si un dato personal hasheado está o no sujeto a la normativa, será de ayuda la Opinión 5/2014 del Grupo de Trabajo del Artículo 29 en la que señalan los tres aspectos clave que deben analizarse para verificar que la anonimización es correcta: Singularización: ¿es posible extraer de un conjunto de datos algunos registros que identifiquen a una persona física? Vinculabilidad: ¿es posible vincular como mínimo dos registros de un único interesado o grupo de interesados? Inferencia: ¿es posible deducir con una probabilidad significativa el valor de un atributo a partir de los valores de un conjunto de otros atributos? Como decíamos, sin duda dependerá del caso concreto. En todo caso, y antes de avanzar con las técnicas de agregación, destacar que la comunidad blockchain trabaja en múltiples técnicas que en el futuro podrían permitir implementar enfoques de anonimización de datos aún más sólidos. Un ejemplo de ellas son las Zero-knowledge proofs (ZKP) o Pruebas de Conocimiento Cero, técnicas criptográficas avanzadas que permiten a alguien presentar pruebas de una declaración sin revelar los datos que subyacen a la misma. Por ejemplo, alguien puede presentar pruebas de que tiene más de 18 años sin revelar su edad real. Las aplicaciones ZKP son muy prometedoras en lo que respecta a la privacidad desde el diseño y la soberanía de los datos personales. Aunque todavía necesitan rodaje. Sea como sea, el sistema basado en blockchain más prometedor y que utiliza pruebas de conocimiento cero es ZCash, que también fue la primera criptomoneda en implementar zk-SNARK. Desde entonces, otros sistemas basados en blockchain también han incorporado pruebas de conocimiento cero en sus soluciones para permitir que las transacciones se verifiquen mientras se protege la privacidad del usuario / transacción. Probablemente el más conocido de los cuales es Ethereum, que implementó zk-SNARK como parte de la actualización de Bizancio (el llamado protocolo AZTEC). Por otro lado, otra técnica avanzada en camino es la llamada encriptación homomórfica. Aquí estamos ante un método criptográfico que permite a alguien solicitar que servidores privados realicen cálculos distribuidos. Si bien los datos subyacentes de estos cálculos nunca se revelan ni se comparten en la cadena de bloques, es en teoría posible obtener una prueba criptográfica de que el resultado agregado de esos cálculos es correcto. De esa forma, es por ejemplo posible cifrar datos, enviarlos a la nube y operar sobre estos datos sin descifrarlos. La nube no tiene la menor idea del contenido de los datos sobre los que está operando, no vé ningún resultado intermedio. La totalidad de los datos permanecen cifrados durante todo el tiempo. De manera que obtienes el resultado cifrado y solamente tú puedes descifrarlo. En eso consiste el cifrado homomórfico. III.- Agregación de datos personales Finalmente llegamos a las técnicas de agregación. Las mismas se pueden utilizar junto a las de ofuscación y encriptación. Por ejemplo, una gran cantidad de datos de interesados podrían ser agregados en una única firma digital que luego fuera incorporada a la cadena. Esa firma serviría luego como la prueba de la existencia de cada uno de los datos sumados. Estas técnicas de agregación dependen de estructuras llamadas Árbol de Merkle, que involucran funciones de hashing haciendo que el proceso sea aún más robusto y potencialmente anónimo. Muy resumidamente: un árbol de Merkle es una estructura jerárquica que se compone de un hash de hashes. Para crearla, se cogen todas las transacciones del bloque y se calculan sus hashes, una por una. A continuación, los hashes resultantes se juntan por parejas y se calcula el hash de la pareja. Esta operación se repite sucesivamente hasta que solo queda un único hash de todo, la raíz de Merkle.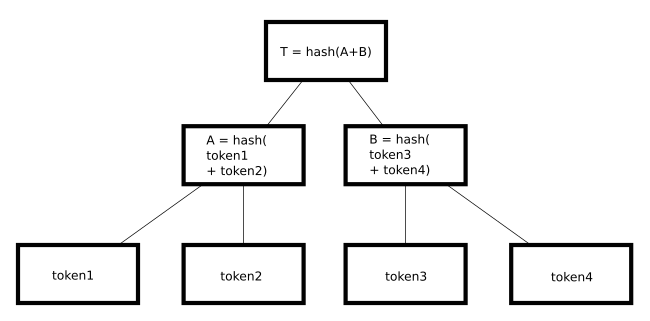
3.2.3.- El ejercicio de derechos y otras cuestiones
Además de identificar a las partes y minimizar el impacto sobre la información personal, hay otros puntos de tensión entre el RGPD y blockchain. Tanto a nivel de principios y obligaciones de la norma, como del ejercicio de derechos. Un primer problema es la base de legitimación al tratar datos en una red descentralizada por completo. Es decir, una cadena pública sin permisos. En esos entornos no siempre es fácil determinar bajo qué bases legales se tratan los datos personales. Por ejemplo, el consentimiento en una cadena pública sin permisos, ¿a quién se lo da un usuario cuando como hemos visto no está claro quién es el responsable de la misma? Se argumenta que al elegir una red descentralizada al completo, el usuario ya está dando su consentimiento de facto. Sin embargo, al RGPD no le entusiasma la idea de una consentimiento que no sea expreso. ¿Recurrimos a la idea de la acción afirmativa en ese sentido? ¿Pero en favor de quién? Algo parecido se plantea cuando el usuario realiza una transacción, ya que podría intentar argumentarse un tratamiento basado en una relación contractual. Sin embargo, nuevamente nos cojea quién hay del otro lado y la parte informativa de esa contratación. Nadie por ahora plantea la posibilidad del interés legítimo como base de legitimación, pero dada la particular naturaleza de la cadena de bloques (un sistema transparente, descentralizado, inmutable y sin intermediarios), quizá tenga mucha lógica plantearse bases de legitimación en esa línea. Al fin y al cabo, todos los participantes en la cadena tienen un interés legítimo en que el sistema haga realidad las características que tan particularmente la definen. Por tanto, y en el caso de las blockchain públicas sin permisos, su estructura tan poco centralizada hace muy difícil aplicar el RGPD. Otra cosa es en cadenas privadas o públicas con permisos, donde seguramente sí sería posible identificar una entidad que opera el producto o servicio y actúa como intermediario entre los usuarios individuales y la cadena de bloques.
3.2.4.- Decisiones individuales automatizadas y smart contracts
Por si no hubiera suficientes preguntas hasta ahora, se plantea también qué pasa con los creadores de los contratos inteligentes. Como ya hemos mencionado, y muy simplificadamente, los contratos inteligentes son software que se puede implementar en blockchain y ser ejecutados independientemente de su (s) creador (es). Un tema importante es que este software solo se ejecuta cuando lo autoriza un nodo de la red, por lo que hay un debate sobre si este software debe ser visto como operado por su creador, por el nodo que lo ejecuta o por ambos. Otra cuestión relacionada con los contratos inteligentes y blockchain es la tratada por la CNIL brevemente y más en detalle por Michèle Finck en su trabajo “Smart Contracts as a Form of Solely Automated Processing Under the GDPR“, relativa a si cuando se usan contratos inteligentes en blockchain, y los mismos contienen información personal, podemos encontrarnos en el escenario del art. 22 RGPD. Es decir, que una de las partes de ese contrato sea objeto de una decisión basada únicamente en el tratamiento automatizado y que la misma produzca efectos jurídicos en el interesado o le afecte significativamente de modo similar. Una primera cuestión respecto al tratamiento automatizado de datos personales es que el interesado debe poder solicitar al responsable de los datos si los mismos se están utilizando para la toma de decisiones automatizadas. Por ello el RGPD estipula que los interesados tienen derecho a ser informados de si se está llevando a cabo dicho tratamiento y, a su vez, tienen derecho a solicitar la intervención humana o impugnar una decisión. Hay quienes creen que esta disposición del art. 22 RGPD podría tener un efecto negativo en la forma en que las personas usan los contratos inteligentes, ya que este tipo de contratos destacan por su potencial para introducir automatización radical en muchos casos. Sin embargo, surge la duda de cómo se podría cuadrar esa automatización radical con lo dispuesto en el RGPD, ya que si los desarrolladores de los mismos tienen que introducir medidas para permitir la intervención humana, la confianza que los participantes depositan en ellos podría reducirse drásticamente. La CNIL ha indicado que si una decisión exclusivamente automatizada surge de un contrato inteligente, la misma es necesaria para su desempeño, dado que permite el cumplimiento de la esencia misma del contrato. Es decir, es la razón por la cual las partes concluyeron el contrato. Ahora bien, el interesado debería poder obtener una intervención humana para expresar su punto de vista y disputar la decisión del contrato una vez que el mismo se haya ejecutado. Eso significa que el responsable del tratamiento debería proporcionar la posibilidad de una intervención humana que permita al interesado impugnar la decisión incluso si el contrato ya se ha realizado. Además, al margen de lo que se haya registrado en blockchain. La realidad es que el trabajo de Michèle Finck deja bastante claro que los contratos inteligentes no serán automáticamente legales conforme al art. 22 RGPD, pero sí puede ser diseñados (volvemos a la privacidad desde el diseño) para ser compatibles con sus requisitos. Michèle Finck considera que si bien eso requerirá un esfuerzo especial y, en algunos casos, un alejamiento de la motivación original en el uso de los smart contracts, los esfuerzos necesarios se superpondrán en parte con el desarrollo continuo de contratos inteligentes más sofisticados. Por ello cree que hay razones para considerar que el futuro de los contratos inteligentes no será el de la automatización total, sino que nos aprovecharemos de los beneficios de la ejecución automatizada y, al mismo tiempo, garantizaremos que eso ocurra de una manera compatible con con el mundo real y el RGPD.4.- Diferentes escenarios y posibles soluciones
Vista la versión larga de los diferentes escenarios y sus particulares tensiones, veamos ahora la versión corta de esta lucha entre nuestra fuerza irresistible y el objeto inamovible. Comencemos por la base de datos corriente y moliente, la centralizada. El modelo tradicional y donde el RGPD se mueve como pez en el agua. En este caso hay poco que explicar ya que es la situación común (todavía no estamos en blockchain :p).
- ¿Quién es el probable responsable?
- ¿Quiénes son los probables encargados?
- ¿Subimos datos a la cadena?
- ¿Se pueden ejercer todos los derechos?
- ¿Podemos controlar las decisiones individuales automatizadas de los contratos inteligentes?
- ¿Hay transferencias internacionales de datos?
- ¿Quién es el probable responsable?
- ¿Quiénes son los probables encargados?
- ¿Subimos datos a la cadena?
- ¿Se pueden ejercer todos los derechos?
- ¿Podemos controlar las decisiones individuales automatizadas de los contratos inteligentes?
- ¿Hay transferencias internacionales de datos?
- ¿Quién es el probable responsable?
- ¿Quiénes son los probables encargados?
- ¿Subimos datos a la cadena?
- ¿Se pueden ejercer todos los derechos?
- ¿Podemos controlar las decisiones individuales automatizadas de los contratos inteligentes?
- ¿Hay transferencias internacionales de datos?
5.- Conclusiones
Visto lo anterior, parece quedar claro que cuanto más nos alejamos del blockchain y sus propiedades (transparencia, inmutabilidad, descentralización y desintermediación), más fácil es hacer respirable la convivencia entre la cadena de bloques y el RGPD. Ahora bien, cuando abrazamos con todo su esplendor a blockchain y su tecnología, los roces entre la fuerza irresistible y el objeto inamovible sin duda saltan a la vista. Así las cosas, ¿qué hacemos? Lo primero será ir viendo cómo estas tensiones comentadas van siendo resueltas por el EDPB, los tribunales, entidades gubernamentales y legisladores. Ahora bien, no podemos decir que blockchain y RGPD sean incompatibles e irreconciliables. Pero sí que la convivencia entre uno y otro debe ser medida caso a caso y con mucha paciencia. Especialmente en estos primeros tiempos. De todos modos, y para proyectos actuales, será bueno tener en cuenta una serie de pautas básicas: 1.- ¿Realmente necesitamos blockchain? Responder bien esta primera pregunta puede resolver multitud de dolores de cabeza. Si la respuesta fuera sí, el proyecto necesita valorar qué tipo de datos se necesitan, quién puede consultarlos, con qué finalidad se trataran, sobre qué base legal o durante cuánto tiempo. Si podemos dar respuesta a esas preguntas sobre el papel, y teniendo en cuenta la privacidad desde el diseño y por defecto del RGPD, entonces quizá nos podamos plantear la viabilidad de utilizar la tecnología blockchain para el tratamiento de los datos.
1 comentario en «La fuerza imparable (RGPD) contra el objeto inamovible (Blockchain)»
Los comentarios están cerrados.